A big part of the research carried out in the K team in driven by applications and evaluated using concrete implementations. By solving specific problems in specific domains, we can explore fundamental challenges in artificial intelligence, knowledge modelling and data science. By building the tools that address those challenges, we provide ways to reuse the results of our research and apply them beyond the scope of their original context. Below are some of the tools built by members of the K team.
Navigating the semantic web
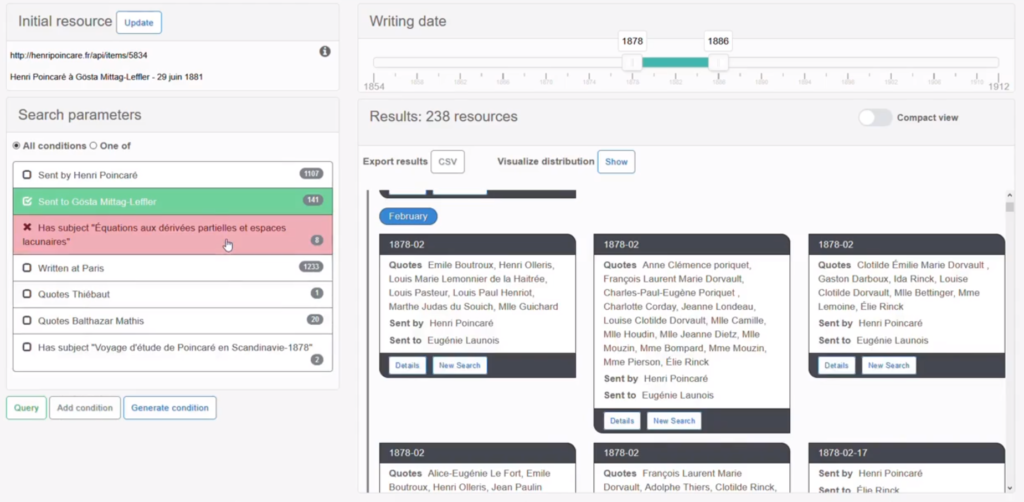
The idea of the semantic web is make knowledge accessible, explorable and interpretable directly through web technologies. RDF (Resource Description Framework) is the base formalism to represent information as graphes living on the web. While they are made to be processable by machines, those graphs can be hard to explore for humans. We designed a system to find interesting resources by exploiting similarities between elements of an RDF graph. A resource can be anything such as an art work, a document, a place, an individual, etc. The results found using this tool are exposed through a time-based interface in which one can navigate through results. First designed for the Henri Poincaré correspondence corpus, this system can be reused with any corpora as long as corpus data is available through a SPARQL endpoint.
The source of the system can be found on github and was described in a paper at the International Joint Workshop on Semantic Web and Ontology Design for Cultural Heritage. A demonstration video is also available.
RDF Editor
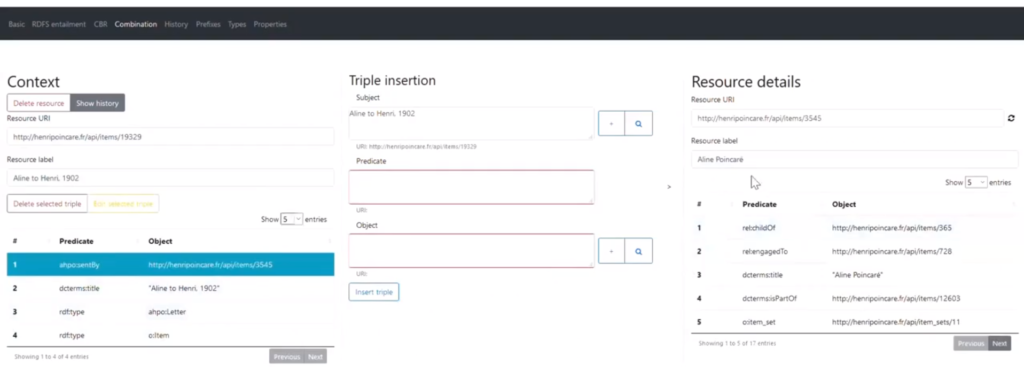
RDF graphs (knowledge graphs) being made for machines, they are generally not only processed by machines, they are also, most of the time, generated by machines. Manually editing an RDF graph can indeed be complex due to the scale and richness of the graph and the flexibility of the formalism. We therefore also designed and developed an tool to assist the editing of potentially large RDF graphs, relying on RDF Schema entailments and case-based reasoning. Originally created to support the creation of the knowledge graph for the correspondence of Henri Poincaré the principles underlying this tool can be applied in other domains.
The source of the system can be found on github and was described in a paper at the ICCBR 2021 conference. A demonstration video is also available.
deltaML
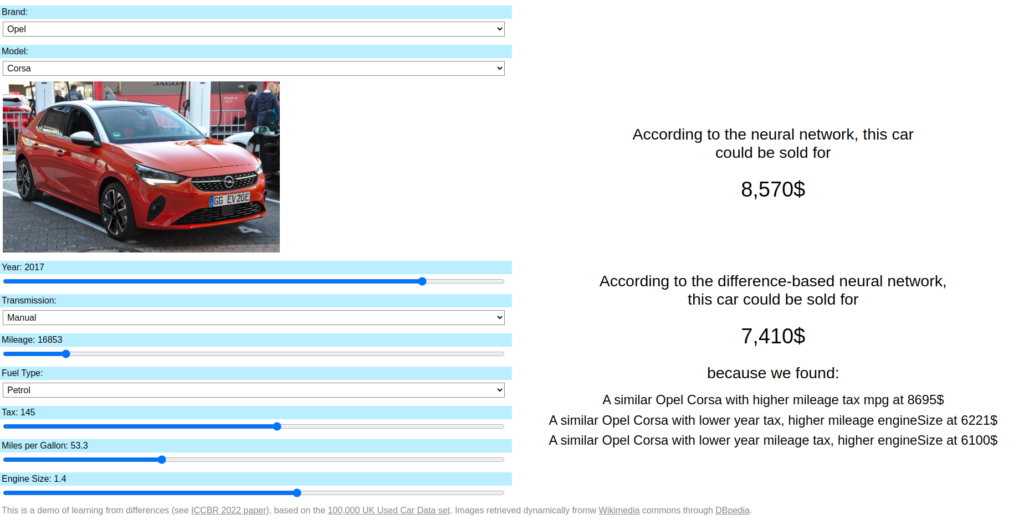
deltaML is a simple library to help using the approach of learning from differences in machine learning. The idea of learning from differences originates from case-based reasoning (CBR) where it is called the case difference heuristic (CDH). In short, instead of applying a machine learning method on the features of the items considered directly to predict a raw value, we apply it to differences between pairs of feature vectors to predict differences in values. The advantages of doing this include that the results might be more explainable (the predicted price of a used car for example is easier to explain than if provided in reference to the real prices of similar used cars). In a paper at the ICCBR 2022 conference, we also showed that: 1- A neural network learning from differences can sometimes outperform a neural network trained in the usual way, 2- learning from differences helps exploit the data more, as multiple case differences can be created for every item in the original training data, and 3- a neural network learning from differences might require significantly less training (in number of epochs) than a neural network trained in the usual way.
A small library tested on simple regression problems with keras-based model is available on github.
OWBO
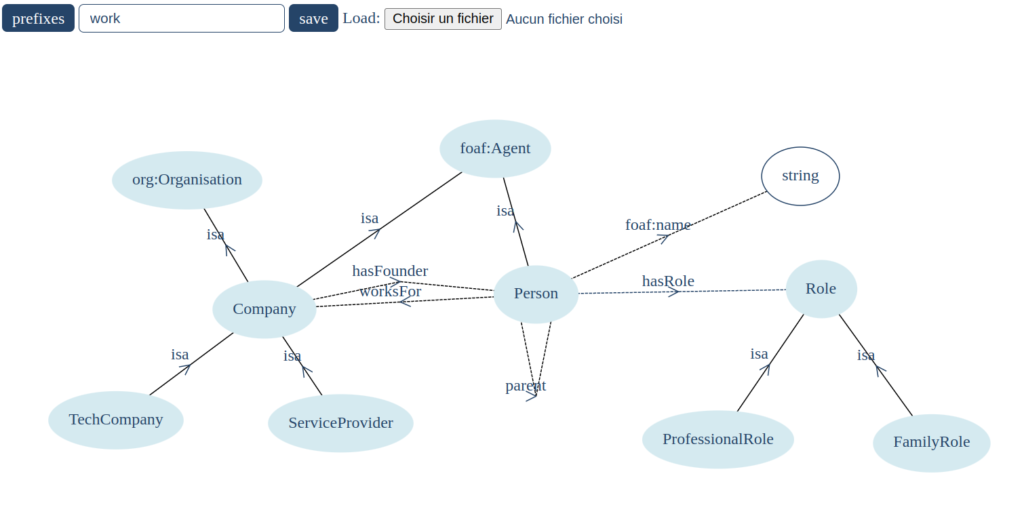
Ontologies are formal conceptual models of a domain, which can be used to structure, understand and provide meaning to data. Existing ontology editors enable users to write complex model. However, it is often the case that, at least when starting an ontology, one mostly only needs basic conceptual constructs, i.e. the ability to create classes and to relate them through relations. In this case, drawing them on a white board is often more efficient than trying to implement such an initial “skeleton” ontology directly in the ontology editor. OWBO aims to provide support for this. It makes it possible to create basic conceptual structures by simply adding and naming classes, and relating them with relations. Clicking in a white space creates a class; clicking on a class starts a relation; and clicking on a second class ends it.
OWBO is developed as a single HTML file and is therefore trivial to install and share from the github repository. It can also be tried online.